[Review] Scaled-YOLOv4: Scaling Cross Stage Partial Network
이번 포스팅에서는 Object detection을 위한 모델 중 하나인 “Scaled-YOLOv4: Scaling Cross Stage Partial Network “를 리뷰해보겠습니다. Scaled-YOLOv4는 YOLOv4의 다음 버전이라고 볼 수 있고, 2021년 2월에 퍼블리시된 논문입니다.

(본 논문의 세 저자들은 YOLOv4의 저자입니다)
리뷰에 앞서, Abstract을 간략하게 정리해보면 다음과 같습니다.
- depth, width, resolution 뿐만 아닌 네트워크의 구조까지 수정하는 network scaling 기법을 제안함
- (논문이 제안된 시점 기준) SOTA 중 가장 높은 AP를 기록함
Introduction
Object detection은 이젠 너무 당연하게 적용되는 기술로 자리 잡았습니다. 효율적인 object detector를 설계하기 위해선 model scaling(모델의 크기를 조절하는 것) 기술이 중요한 요소 중 하나인데, 실시간으로 활용하며 높은 정확도를 달성하기 위해서는 계산 비용과 정확도 간에 trade-off가 중요하기 때문입니다.
가장 보편적으로 사용되는 model scaling 기술은 backbone의 depth(CNN에서 convolutional layers의 개수)와 width(convolutional layer에서 convolutional filters의 개수)를 바꾸고 그에 맞게끔 CNN을 학습시키는 방법입니다. 대표적인 예시로 ResNet이 있습니다. ResNet은 뒤에 숫자들이 붙는데, 이 숫자들이 레이어의 개수를 뜻합니다. ResNet-152나 101같이 레이어가 많은 모델은 클라우드 서버의 gpu를 사용해야 하고, 50이나 34는 개인 컴퓨터의 GPU로도 충분합니다.
다른 기법으로는 NAS(Network Architecture Search)기법으로, 네트워크의 가장 효율적인 구조를 디자인하는 기법입니다. 최근엔 object detection task를 위해 NAS와 model scaling 기법이 사용되는 SpineNet과 EfficientDet과 같은 모델이 있습니다.
이전에 본 논문의 저자들이 YOLOv4의 backbone으로 NAS를 통해 최적화된 구조를 가진 CSPDarknet53을 제안했습니다. 본 논문에서는 YOLOv4를 기반으로 model scaling 기술을 발전시켜 scaled-YOLOv4 모델을 제안합니다.
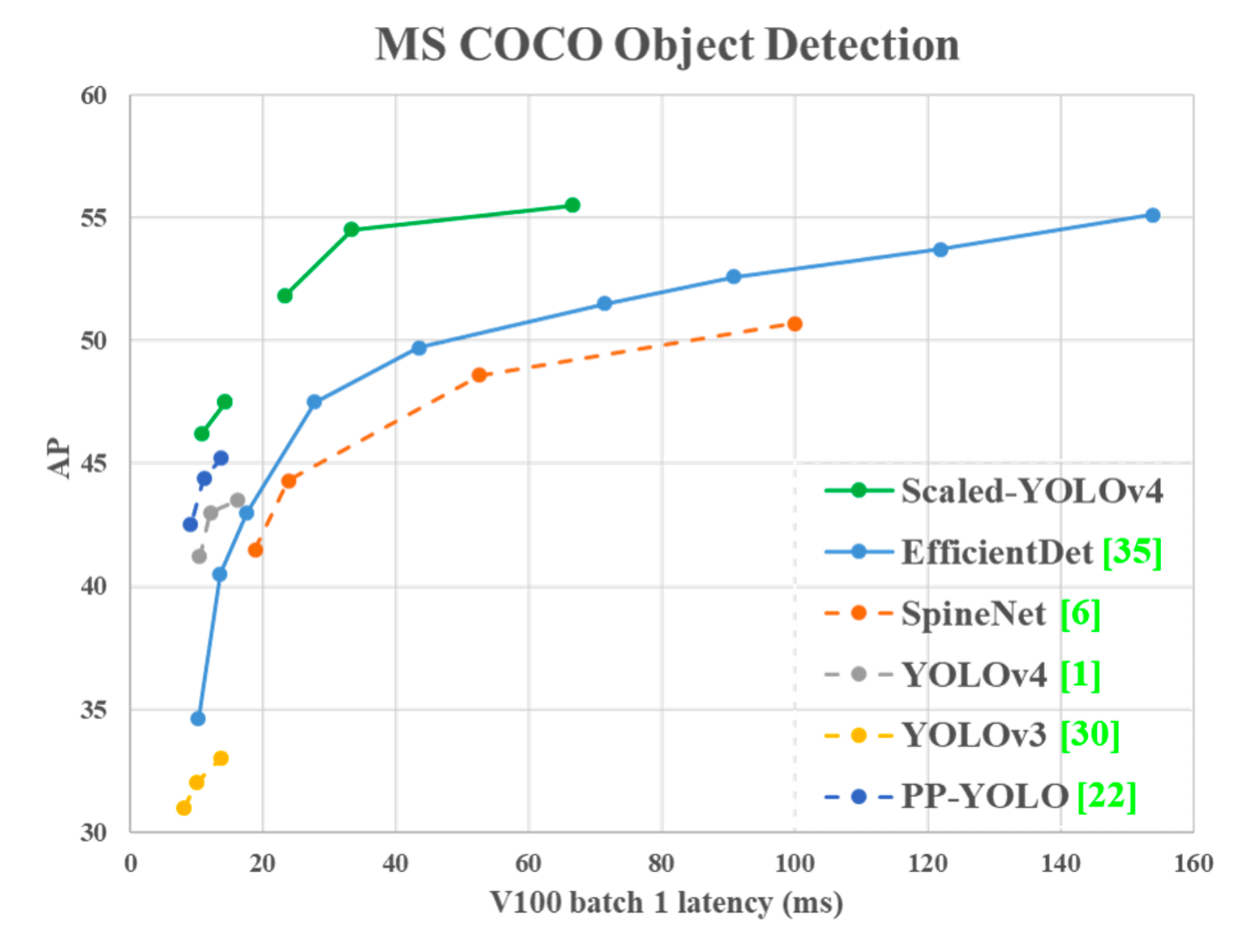
본 논문에서는 YOLOv4를 재디자인하고 YOLOv4-CSP를 제안하며, YOLOv4-CSP를 기반으로 scaled-YOLOv4를 발전시킵니다. YOLOv4-large 모델과 YOLOv4-tiny 모델을 개발하였고, 속도와 정확도 간에 최고의 Trade-off를 달성하며 실시간으로도 16FPS ~ 60FPS의 속도로까지 사용이 가능합니다.
1. 작은 레이어수를 가진 CNN에서도 계산량과 메모리 간에 균형을 이룰 수 있는 강력한 model scaling 기법을 디자인합니다.
2. 큰 크기의 object detector도 심플하지만 효율적인 성능을 내도록 디자인합니다.
3. model scaling 요소들과 성능 간에 상관 관계를 분석합니다.
4. FPN(Featrue pyramid network)구조가 once-for-all-structure(OFA network, 전체 네트워크 중 일부분을 선택)입니다.
5. 위의 기법들을 사용하여 YOLOv4-tiny와 YOLOv4-Large를 개발했습니다.
Related Works
넘어가겠습니다. (YOLOv4 논문을 참고하시는 것을 추천드립니다.)
Principles of model scaling
본 섹션에선 YOLOv4에서 다룬 개념들이 많이 등장하기 때문에 간략하게 설명하고 넘어가도록 하겠습니다.
1. General principle of model scaling
일반적인 CNN 모델에서, 파라미터수 및 계산 비용을 계산할 때 가장 큰 요소 세 가지는 이미지 크기, 레이어의 수, 채널의 수 입니다. CNN모델 3개(ResNet, REsNext, Darknet)을 이용해서 실험을 하는데, b개의 base layer channels 크기의 k개의 레이어를 가진다고 가정합니다. 이미지 크기, 레이어 수, 채널 수의 scaling factor를 각각 α, β, γ라고 했을 때, 아래와 같이 요소에 따라 계산 비용이 증가함을 볼 수 있습니다.

CSPNet은 CNN의 계산 시간은 줄이고 정확도는 늘려주는 네트워크 기법인데, 이를 3개의 모델에 적용하면 다음과 같이 FLOPs가 줄어듭니다. (간략하게 말하면 입력되는 base layer feature를 쪼개어 backbone은 유지하되 feed and back-propagation 시 가중치의 중복을 줄이는 기법.)

따라서 Scaled-YOLOv4에서는 네트워크를 CSP화(CSP-ized)합니다.
2. Scaling Tiny Models for Low-End Devices
Low-end devices에서 모델을 사용할 땐 계산량, 속도 뿐만 아니라 하드웨어의 리소스, 즉 메모리 대역폭, MACs, DRAM 트래픽 등까지 고려해야합니다. 하지만 적은 계산량으로도 높은 정확도를 달성해야죠.
본 논문에서는 적은 계산 복잡도를 가진 OSANet으로부터 영감을 받아 tiny model을 설계합니다.

OSANet
또한 계산 속도에서 최고의 trade-off를 달성하기 위해, CSPOSA(CSP+OSA)Net에서 블록 간에 gradient truncation, 즉 PCB를 적용합니다. (YOLOv4-tiny에서 그림 설명) 그럼 아래 테이블과 같이 계산량이 줄어듭니다.

아래 섹션의 그림만 보고 이해하면, OSANet의 구조와 동일하게 concat을 가져가고, base layer의 b를 2개의 g로 나눠준 뒤 계산합니다. 따라서 1/2크기로 계산되는 g를 이용함으로써 계산량을 줄입니다.
3. Scaling Large Models for High-End GPUs
CNN 모델을 scaling up, 즉 크게 만든 뒤에는 실시간 inference 시 높은 정확도와 빠른 시간을 유지해야 합니다. 그러기 위해 많은 scaling factors 중에서도 최고의 조합을 찾아야하는데, input, backbone, neck 세 가지를 얘기합니다.

Object detection 과정에서는 이미지 내에서 각각의 object의 위치와 크기까지 예측을 합니다. 이러한 정보는 feature vector의 receptive field와 연관이 있습니다. CNN에서는 stage와 연관이 되어있고, FPN(Feature Pyramid Network)의 구조의 경우 상위층으로 갈 수록 더 큰 object도 제대로 예측할 수 있습니다. 실험을 했을 때, 입력 이미지 사이즈와 stage개수를 조절하는 게 가장 큰 성능 효과가 있었습니다.

Scaled-YOLOv4
가장 중요한 모델 소개입니다. 따라서, 본 논문에서는 Scaled-YOLOv4를 일반 GPU, low-end GPU, high-end GPU용으로 디자인합니다.
1. CSP-ized YOLOv4
YOLOv4는 일반 GPU에서 실시간으로 object detection이 가능한 모델입니다. 이 YOLOv4를 YOLOv4-CSP로 다시 디자인하여 속도-정확도 면에서 최고의 trade-off를 달성하였습니다.
Backbone
YOLOv4에서 사용한 CSPDarknet53은 원래 down-sampling convolution이 residual block에 포함되지 않았습니다. 전체 계산량을 따져봤을 때, Darknet stage에서 레이어의 수가 1을 초과한다면 계산 면에서 좋아져, CSPDarknet53의 residual layer의 숫자를 1–2–8–8–4로 각각 설정하였습니다. 또한 첫 번째 CSP stage를 original Darknet residual layer로 바꿨습니다.
Neck

YOLOv4에서 사용한 PAN(Path Augmented Network)은 (a)그림과 같이 계산하였습니다. 본 논문에선 CSP-ization하여, (b)와 같이 CSPNetwork로 구성하여 40%의 계산량을 감소시켰습니다.
SPP(Spatial Pyramid Pooling)
변화 없습니다.
2. YOLOv4-tiny
low-end GPU device를 위해 디자인된 YOLOv4는 위에서 설명한 원리들을 기반으로 제안하였습니다. (CSPOSANet에 PCB구조를 적용) 각각의 stage의 채널 개수와 neck은 YOLOv3-tiny와 동일합니다.

3. YOLOv4-Large
Cloud GPU용의 YOLOv4-Large는 높은 정확도 달성이 목적입니다. 따라서 CSP를 완전히 적용한 YOLOv4-P5를 디자인하고, scale up시켜 P6과 P7도 디자인하였습니다.

본 모델들에선 입력 이미지 크기와 stage의 개수를 scaling하였습니다. inference time를 봐가며 width scaling도 추가적으로 적용하였습니다.
실험상 YOLOv4-P6의 경우, width의 scaling factor=1일 때 실시간 검출 시간이 30 FPS가 나왔다고 합니다. YOLOv4-P7의 경우, width scaling factor=1.25일 때 16 FPS가 나왔다고 합니다.
Experiments
Scaled-YOLOv4 for object detection
가장 중요한 object detection task에서 전체 SOTA 비교 table만 첨부합니다.

마치며
저는 원래 리뷰 시 Conclusions는 읽고 작성은 잘 안 하는 편인데, YOLOv4-large에서는 AP가 COCO 데이터셋에서 56%까지 나왔다고 하네요. 정말 엄청난 발전이라는 생각이 듭니다.
Experiments와 Conclusions은 본문의 테이블을 참고드리는 것을 추천드립니다. 이유는 변형이 많은 모델인 만큼 ablation study 역시나 많고 결과 테이블도 적지 않은데, 사실 이 모델은 무엇이 가장 좋다고 단정지어 말하기 어렵습니다. 본문에도 계속 강조하듯, speed와 accuracy 간에 trade-off가 강력하여 그 만큼 선택의 폭이 굉장히 넓습니다. 그렇기 때문에 본인의 필요에 따라 Experiments를 살펴보시는 것을 권장합니다.
YOLOv4와 같이, 딥러닝 관련 최신 기술은 엄청나게 때려박았다는 것을 느꼈고 제가 최신 동향을 잘 못 따라가고 있다는 것도 느꼈습니다.^^;; 정리하면서도 100% 이해가 되지 않는 부분이 있어(계산이나 알고리즘 부분) 추가적으로 공부가 더 필요할 듯 합니다.
그 만큼 틀린 부분 밑 설명이 부족한 부분이 많을 수 있습니다. 언제든지 댓글로 틀린 부분 있으면 알려주세요. 감사합니다.
스크랩 시 출처를 기재해주세요.
+
실제로 CSP를 사용해보았는데, 속도가 꽤 빠르네요!