이번 포스팅에서는 2021 CVPR에서 Best Student Paper Honorable Mentions을 수상한 논문 중 하나인 “Real-Time High-Resolution Background Matting”에 대해서 리뷰해보려고 합니다.

리뷰에 앞서, Abstract을 간략하게 정리해보면 다음과 같습니다.
- 일반적인 GPU로 4K 영상에서는 30fps, HD 영상에선 60fps로 배경 제거 및 교체가 가능함
- 높은 퀄리티의 alpha matte를 계산하여 머리카락과 같은 세부 정보를 보존
- 2개의 Neural network 사용 : 첫 번째 네트워크는 low-resolution으로 결과 추출하고, 두 번째 네트워크에서 patch 단위로 high-resolution으로 refine
- 사용된 데이터셋은 VideoMatte240K, PhotoMatte13K/85
- SOTA에 비해 드라마틱한 성능 및 속도 향상이 나타남
내용이 꽤 상세한 편이니, 급하신 분들은 필요한 섹션만 읽으시는 걸 추천드립니다!
Introduction
Background replacement(뒷배경 변경)는 영화에서 특수효과로 사용되기도 하고, 요즘 같은 코로나 시국에는 Zoom이나 GoogleMeet 같은 영상 통화 시스템에서 많이 사용되기도 합니다.

그런데 이 기능을 잘, 혹은 제대로 사용하기 위해선 사용자가 그린 스크린에 있거나 다른 특수 장치를 사용해야 좀 더 완벽하게 배경이 제거 및 교체가 됩니다.

많은 툴들이 뒷배경 변경 기능을 제공하기는 하지만, 위의 그림과 같이 머리카락이나 안경 안에 비친 배경(가운데 사진) 등에서는 적용이 안되는 경우가 많습니다. 또한 지금까지 제안되어 온 대부분의 방법들은 배경 교체 성능 자체는 좋지만, 고화질 이미지에서 실시간으로 적용할 수 없습니다.
본 논문은 높은 품질의 영상에서도 실시간으로 적용되는 배경 교체(image matting) 모델에 대해 제안합니다. 4K(3840x2160) 영상에서는 30fps, HD(1920x1080) 영상에서는 60 fps의 성능을 보입니다.
지금까지 제안된 SOTA 배경 교체 기법은 512x512 해상도에서 8fps의 성능까지만 가능했습니다. 고화질의 영상일 수록 메모리 부족 및 학습 시간이 느려지기 때문이고, 많은 양의 데이터셋과 레이블(알파 매트)이 필요하기 때문입니다.
본 논문은 이러한 문제를 해결하기 위해, 크로마키 소프트웨어로 추출한 고해상도의 전경 레이어와 알파 매트를 사용하여 모델을 학습시킨 뒤, 공개된 데이터셋으로 한 번 더 학습시킵니다.
또한 네트워크를 만들 때, 상대적으로 영상 안에서 조정이 필요한 영역이 필요하지 않은 영역에 비해 적은 것에 집중합니다. 저화질의 영상 안에서 조정이 필요한 부분을 체크하여, 고화질의 영상에서 수정한다면 비교적 적은 비용이 드는 것을 알 수 있습니다. (SOD에서 적지 않게사용되는 기법입니다.)
Dataset
많은 양의 고화질 영상을 얻기가 어렵기 때문에, 본 논문에서는 본인들이 획득한 데이터셋과 public 데이터셋을 함께 사용합니다.
Publicly available dataset
- Adobe Image Matting(AIM) dataset : 269 training set, 11 test set, 평균적으로 1000x1000의 해상도
- Distinctions-646 : 362 training set, 11 test set, 평균적으로 1700x2000의 해상도
해당 데이터셋의 레이블은 직접 수동으로 그려 정확합니다. 하지만 총 631개의 학습셋으로는 인간의 자세나 고화질 영상에서의 디테일한 부분에 대한 variation까지는 학습하기가 어려워, 2개의 추가적인 데이터셋을 더 사용합니다.

- VideoMatte240K
Adobe After Effects를 사용하여, 484개의 고화질 그린 스크린 영상에서 총 240,709개의 알파 매트와 전경 레이어를 획득했습니다. (4K : 384개, HD : 100개) 학습셋은 479개, 검증셋은 5개의 영상으로 나눴습니다. 데이터셋에는 다양한 인간, 옷, 포즈 등이 있어 모델을 좀 더 robust하게 학습시킬 수 있습니다.
2. PhotoMatte13K/85
두 번째 데이터셋은 그린 스크린에서 촬영된 이미지를 크로마키 알고리즘을 통해 13,665장의 데이터셋을 획득했습니다. 학습셋과 검증셋은 13,165 : 500으로 나눴습니다. 이 데이터셋은 촬영된 사람의 포즈가 비교적 한정적이나, 평균적으로 2000x2500의 높은 해상도를 가져 머릿결 등의 디테일한 부분을 캐치할 수 있습니다. (PhotoMatte13K의 경우, 라이센스 문제로 공개가 어려워 테스트셋만 따로 공개했습니다.)
또한, 8,861장의 이미지를 Flickr와 Google에서 얻어 학습, 검증, 테스트셋을 8,636:200:25로 나누어 사용했습니다.
Approach
그렇다면 이 모델은 어떤 식으로 영상에서 새로운 배경으로 교체할까요? 자세히 알아보겠습니다.
이미지 𝐼와 배경 𝐵가 주어지면 알파 매트와 전경 레이어 𝐹를 예측합니다. 이렇게 획득한 값으로 새로운 배경(𝐵’)으로 교체된 새로운 이미지(𝐼’)를 얻는 수식은 다음과 같습니다.
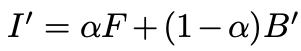
앞에 항에서 인물 정보를 획득하고, 뒤에 항이 새로운 배경 정보를 획득하여 두 값을 더하여 새로운 이미지를 획득한다고 볼 수 있습니다.
본 논문에서는 𝐹를 구할 때 바로 구하는 게 아니라 𝐹의 residual(잔차)인 𝐹ᴿ을 통해 획득합니다. (𝐹ᴿ = 𝐹-𝐼)
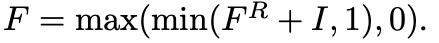
이 수식을 통해 학습 성능을 더 올릴 수 있습니다.

고화질 영상에서의 matting(배경 교체)기법에서 가장 해결하기 어려운 점은 메모리와 학습 시간입니다. 그림에서 보듯, 사람(foreground)으로 예측된 부분의 픽셀들은 매우 넓은 영역에 속하고 주의해야 할 세밀한 부분(머리카락, 안경 등)은 굉장히 적은 부분입니다.
이 점을 고려하여, 모든 네트워크에서 고화질의 영상을 처리하는 것이 아니라 전체 영상에서 세밀하게 처리해야 할 부분만 고화질 영상을 이용하여 2 단의 네트워크를 사용하였습니다.
Neural Network
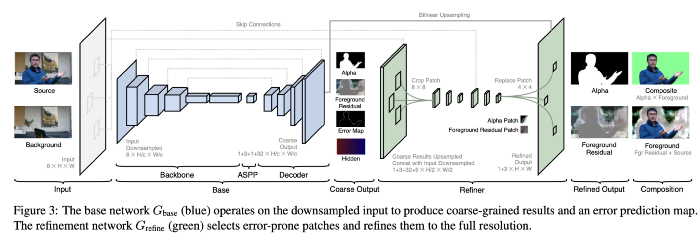
네트워크 구조는 앞단의 베이스 네트워크인 Gbase, 뒷단의 조정 네트워크인 Grefine으로 이루어져 있습니다.
1. Base Network
base network는 DeepLabV3와 DeepLabV3+의 구조인 fully-convolutional encoder-decoder 네트워크 구조를 사용합니다. 2017년, 18년에 semantic segmentation에서 가장 좋은 성능을 달성했던 네트워크입니다.
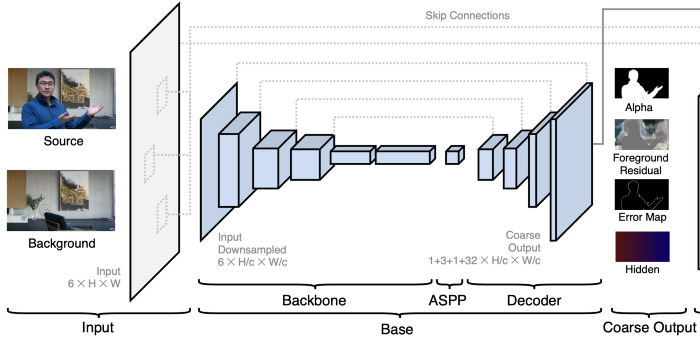
Gbase는 이미지𝐼와 인물(foreground)을 제외한 배경 𝐵를 입력받고, 총 4개의 outputs을 출력합니다. 파라미터 c를 이용하여 임의의 크기의 이미지𝐼를 downsample하여 입력합니다.
Gbase는 3개의 모듈로 이루어져 있습니다.
1) Backbone
Gbase의 encoder backbone은 ResNet-50을 사용했으며, 속도 및 성능의 trade-off에 따라 ResNet-101과 MobileNetV2로도 바꿔 사용할 수 있습니다.
2) ASPP (Atrous Spatial Pyramid Pooling)
backbone 이후에, DeepLabV3에서 사용한 ASPP가 붙습니다. (ASPP에 대한 자세한 설명은 생략하겠습니다)
3) Decoder
decoder 네트워크는 backbone과 skip-connection으로 이어져있습니다. Decoder의 자세한 구조는 원문을 참고 바랍니다. (convolution, BN 등…)
4가지의 outputs은
1)coarse-grained alpha matte 𝜶𝑐 (덩어리 져 출력됨)
2) foreground residual 𝐹ᴿ𝑐
3) 에러맵 𝐸𝑐
4) Hidden features (32채널) 𝐻𝑐입니다.
2. Refinement Network
Base network에서 나온 4개의 output은 Grefine에 입력됩니다. 계속해서 Grefine은 연산량을 줄이는 역할이라고 했죠. Gbase가 전체 영상에서 동작하는 반면에, Grefine은 patch 단위에서 동작합니다.
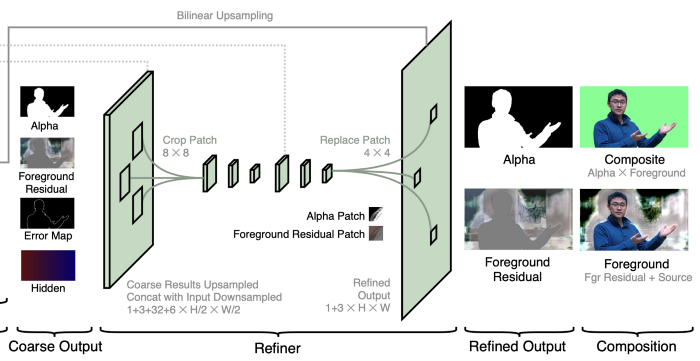
Grefine의 조정 과정은 2단계로 진행되는데, 원래 해상도의 1/2와 전체 해상도에서 진행이 됩니다. 조정 과정 중 총 k개의 patches를 사용합니다. (k는 성능 및 계산 시간에 따라 바꿀 수 있는 파라미터값입니다.)
조정을 하게 되는 patch가 어떤 patch냐 하면, 앞서 Gbase에서 획득된 에러맵 𝐸𝑐에서 선택된 patch입니다. 본 논문에선 c=4를 이용하여, 영상이 원래 해상도에서 1/4 크기로 리샘플링됩니다. 즉 원래 해상도에서 각 픽셀들이 4x4크기의 patch가 됩니다.
그런 다음, 𝐸4에서 가장 높이 예측된 에러값을 가진 patch의 위치를 k개 뽑아 픽셀값을 조정합니다. original resolution에서 조정되는 총 픽셀의 수는 16k개 입니다.
먼저, 원본의 1/2의 해상도를 가진 4개의 output과 입력 이미지 𝐼, 배경 B까지 concat합니다. (1+3+32+6) x (H/2) x (W/2)의 크기를 가집니다. (C,H,W)
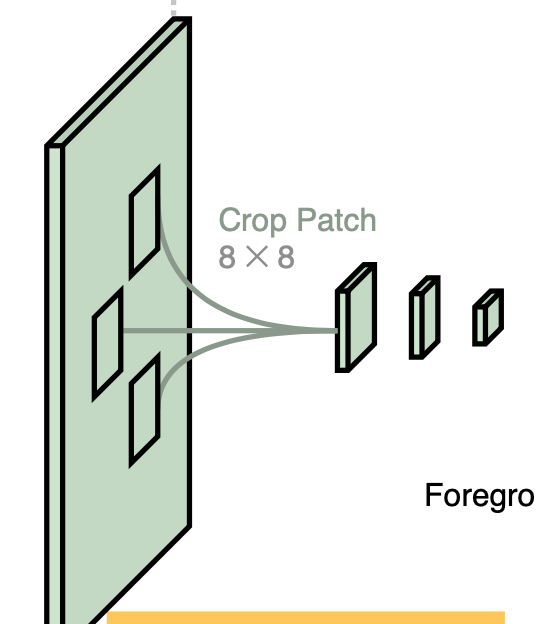
𝐸4에서 선택된 에러의 위치 주변으로 8x8 크기의 패치를 자르고, 2개의 3x3 convolution 레이어를 통과시켜 4x4로 패치 크기를 감소시킵니다. 이를 다시 8x8 크기로 늘려 원래 해상도의 이미지 I와 배경 B에 해당 패치를 결합합니다. (원본 해상도의 영상에서 에러 위치 선택 완료)
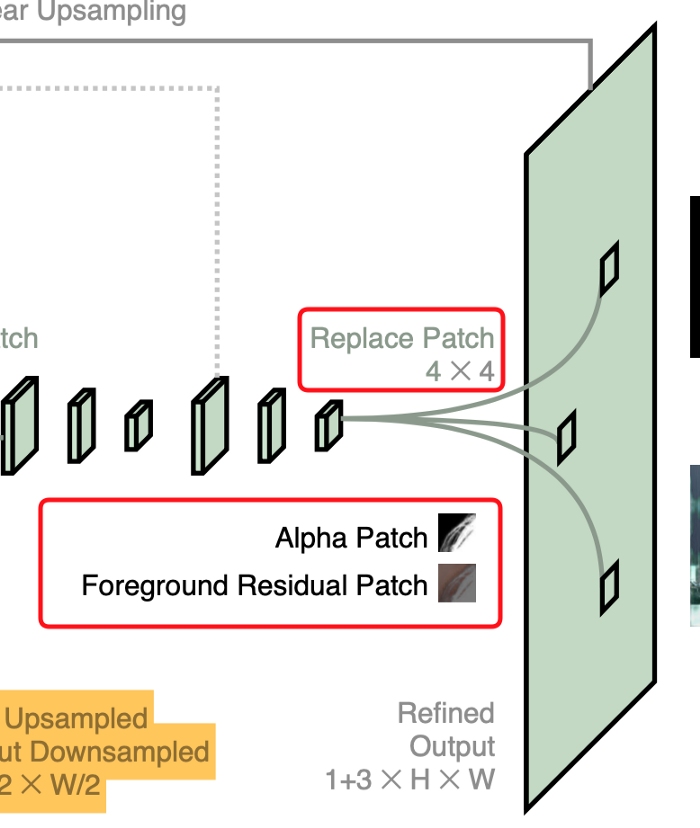
다시 3x3 convolution을 하여 4x4 크기의 알파 매트 𝜶𝑐와 전경 레이어의 잔차 𝐹ᴿ𝑐를 획득합니다. 이를 다시 원래 해상도로 upsampling하여 최종적으로 알파 매트 𝜶와 전경 레이어의 잔차𝐹ᴿ로 각각의 4x4 패치를 바꿉니다.
(번역이라 말이 많이 이상하지만 원문을 읽으면 이해가 갈 겁니다.)
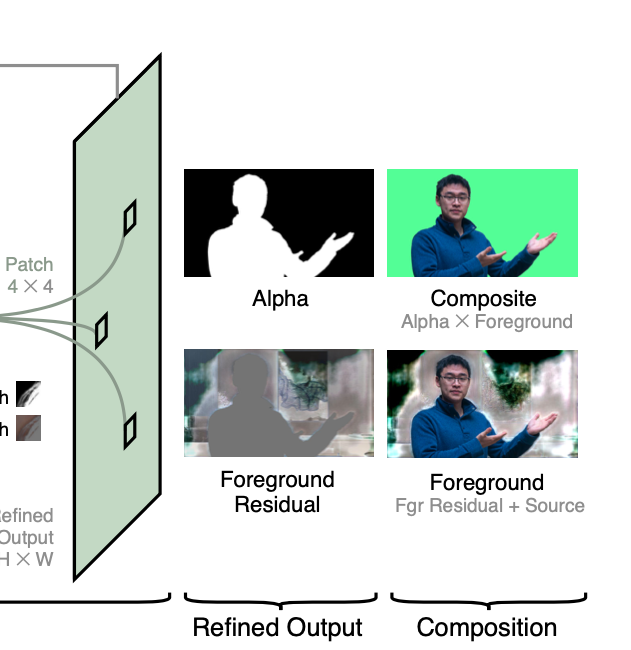
이렇게 조정된 알파 매트와 전경 레이어의 잔차 𝐹ᴿ를 획득할 수 있고, 전경 레이어 𝐹와 알파 매트 𝜶를 곱하면 Composite를(1행 2열 이미지), 전경 레이어 잔차와 입력 이미지를 더하면 전경 레이어를 획득할 수 있습니다 (2행 2열)
Training
모델의 학습 방법입니다.
1.Dataset and pre-processing
데이터셋은 알파메트와 전경 레이어입니다. overfitting을 방지하기 위해 data augmentation을 하였습니다. (affine transformation, horizontal flipping, 밝기, hue와 saturation 조정, blurring 및 sharpening, random noise) 또한 misalignment(정렬이 맞지 않는 것)와 그림자(shadow) 추가를 통해 실제 환경처럼 구성하였습니다.
이미지는 mini-batch로 랜덤하게 크롭하였는데 영상의 height와 Width는 1024~2048 사이로 정해졌습니다.
2. Loss function
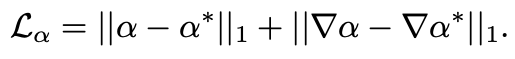
GT인 𝜶*로부터 𝜶를 학습하기 위해 L1 loss를 사용합니다. (오른쪽 항은 알파 매트의 Sobel gradient)
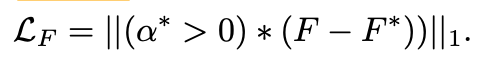
앞서서, 전경 레이어는 그의 잔차인 𝐹ᴿ을 통해 예측을 한다고 했습니다. L1 loss는 GT가 0 이상인 픽셀에서만(실제 투명한 부분) 동작합니다. 예측된 전경 레이어 𝐹와 GT인 𝐹*간의 차이를 계산하며 그 에러를 점점 줄여갑니다.
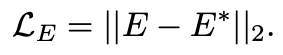
조정할 부분을 선택할 땐 에러맵 𝐸를 사용한다고 했죠. 에러맵과 에러맵의 GT 간에 MSE(Mean Squared Error)를 계산하여 에러를 점점 줄여갑니다.
이 loss는 예측된 알파 매트와 GT간에 차이가 클 때 에러맵의 값이 크게 만들어줍니다. GT 에러맵은 학습하는 동안에 계속 업데이트 되며, 예측된 알파 매트의 품질을 더 높여줍니다. 에러맵은 점점 수렴하게 되면서 복잡한 부분(머리카락 등)에서도 에러를 잘 예측하게 됩니다.
base network는 1/c의 해상도에서 동작할 때 다음과 같은 loss function을 사용합니다.
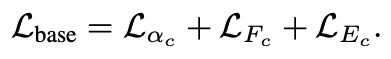
refinement network는 다음 loss function을 사용합니다.
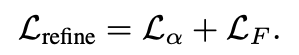
3. Experimental setup
본 모델의 backbone과 ASPP모듈은 DeepLabV3에서 semantic segmentation용으로 ImageNet과 Pascal VOC 데이터셋을 사용하여 사전학습된 weight를 사용합니다. 모델 중 base network를 먼저 충분히 학습시킨 뒤 refinement network를 추가하여 같이(Jointly) 학습시킵니다. Optimizer는 Adam을 사용하였고, 자세한 내용은 원문을 참고하세요.
데이터셋은 Gbase : VideoMatte240K → Jointly : VideoMatte240K → Jointly : PhotoMatte13K → Jointly : Distinctions-646 순으로 사용하여 학습했습니다.
양이 많고 다양한 포즈를 가진 데이터셋으로 먼저 모델을 robust하게 만들고, 고해상도의 영상으로 detail한 부분을 살린 뒤 높은 퀄리티의 public dataset으로 모델의 성능을 더 높였습니다. (AIM 데이터셋은 테스트셋으로만 사용하였습니다. 이에 관한 내용은 섹션 6에서 설명합니다.)
Evaluation
성능 평가를 위해 두 개의 trimap-based 기법인 Deep Image Matting(DIM), FBA Matting(FBA)를 사용하였고, background-based 기법 중 하나인 Background Matting(BGM)을 사용하였습니다.
DIM은 입력 사이즈가 320x320으로 고정되어있고, FBA는 메모리 문제로 HD 영상 까지만 가능합니다. BGM 모델은 본 모델의 데이터셋을 사용하여 학습시켰습니다.
1. Composition datasets
테스트를 위해 AIM, Distinctions, PhotoMatte85 데이터셋을 사용하여 한 개의 샘플 당 5개의 배경사진을 합성했습니다. 실제 데이터처럼 구성하기 위해 컬러 조정, 노이즈 등을 추가하였고, threshold와 모폴로지 연산을 통해 알파 매트의 GT의 trimaps를 획득했습니다.
사용된 metrics는 다음과 같습니다.
* 알파 매트와 전경 레이어 : MSE(Mean Squared Error), SAD(Sum of Absolute Difference), Grad(spatial-GRADient metric)
* 알파매트 : Conn(connectivity)
정량적인 결과입니다.
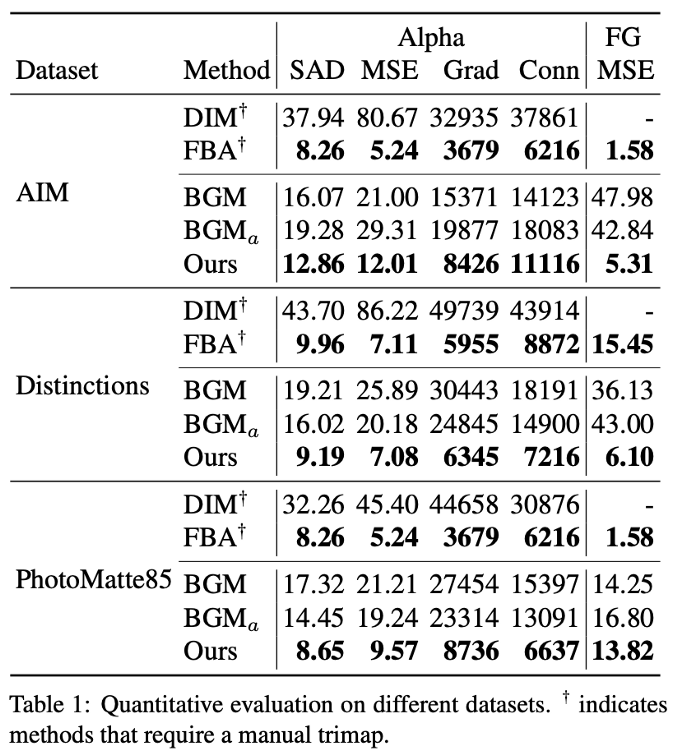
테이블을 보면, background-based 기법인 BGM에 비해 모든 지표가 좋은 것을 볼 수 있습니다. trimap-based 기법 중 SOTA인 FBA보다는 조금 낮은데, 이는 trimaps를 manually 획득하기 때문에 더 정밀하기 때문에 그렇고 속도는 훨씬 빠르다고 합니다. (속도는 뒤에서 더 설명 예정…)
2. Captured data
실제 데이터(real-world)에서 성능은 어떤지를 확인해보기 위해, 다양한 포즈와 주변 환경의 사진 및 영상을 이용합니다. 영상은 스마트폰(삼성 S10+, 아이폰 X)과 카메라를 사용하여 HD와 4K를 획득했습니다.
실제 환경에선 trimaps를 수동으로 만들 수 없으므로, trimaps는 DeepLabV3+의 segmentation 결과 morphing하여 사용하였습니다.

이미지를 보면 제안하는 모델이 더 디테일한 결과를 출력함을 볼 수 있습니다. refinement model이 원본 해상도에서 동작하다 보니 512x512라는 해상도 한계가 있는 BGM에 비하여 훨씬 성능이 좋아보입니다 FBA의 경우 좋은 결과를 보이긴 하지만, 실제로는 연산량 때문에 일반적인 GPU에선 HD 이상의 영상을 사용할 수 없습니다.
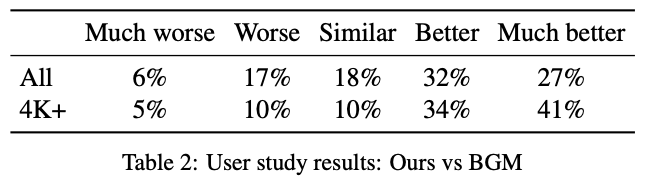
BGM 논문의 테스트 영상과 본 논문에서 획득한 영상 및 사진을 총 34 프레임 추출하여, 40명의 사람들에게 BGM과 제안된 모델의 성능을 비교해달라고 하였습니다. 위의 테이블은 그에 대한 결과입니다. 모델이 BGM보다 낫다면 “Better” 이상을, 아니라면 “Similar” 이하를 선택하게 했고, 결과는 위의 테이블과 같습니다. 59%의 사람들이 제안된 모델의 성능이 더 좋다고 평가했습니다.
3. Performance comparison
이 섹션에서는 BGM에 비해 제안된 모델이 더 작고 빠름을 보여줍니다.
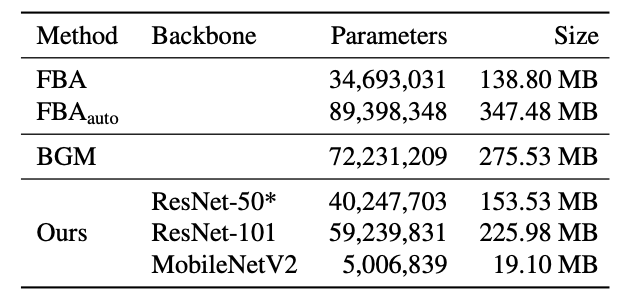
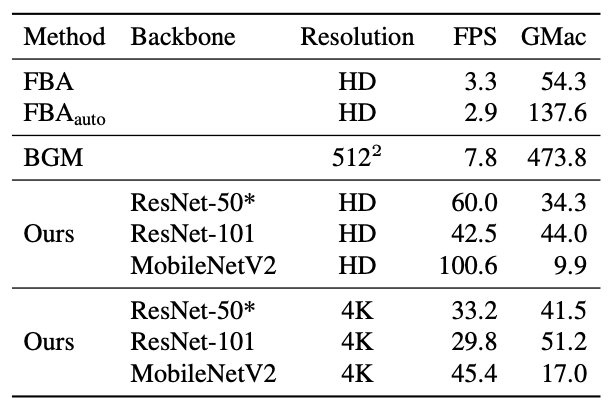
제안된 모델은 BGM에 비해 파라미터 수가 55.7%밖에 되지 않고, Nvidia RTX 2080 Ti GPU에서 batch size 1로 HD 60fps, 4K 30fps가 가능합니다. BGM이 512x512에서도 7.8fps였던 것을 감안하면 엄청난 속도 향상입니다.
backbone을 MobileNetV2로 바꾼다면 4K는 45fps, HD는 100fps까지도 가능합니다.
4. Practical use
크로마키는 배경 변환 중 가장 많이 사용되는 기법인데, 사람에게 조명을 비추면 그린 스크린에 그림자가 져 성능이 떨어집니다.

이미지를 보면 크로마키와 동일하게 조명을 비췄을 때 제안된 모델이 좀 더 디테일한 부분까지 캡처함을 알 수 있습니다.
Ablation Studies
Role of our datasets
앞서서 데이터셋에 대해 설명할 때, 여러 데이터셋을 사용하여 학습시킨다고 했습니다.
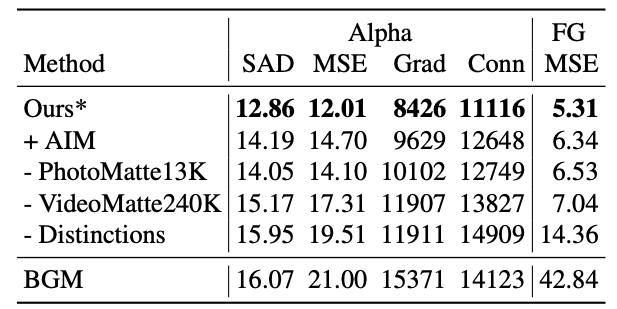
테이블을 보면, 데이터셋을 추가 및 제거할 때마다 변하는 성능을 확인할 수있습니다. 앞선 섹션에서 AIM데이터셋은 테스트용으로만 사용된다고 했죠. AIM데이터셋 자체가 해상도와 품질이 낮고, 샘플 수도 적기 때문에 모델의 성능을 낮춘다고 합니다.
Role of the base network
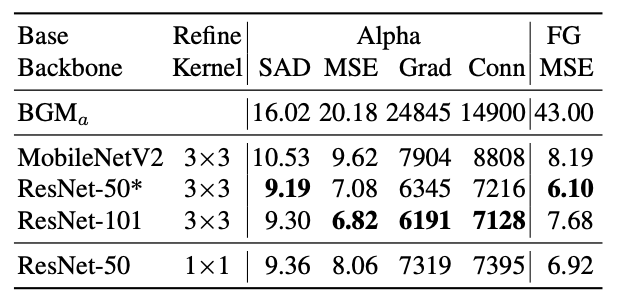
Encoder backbone으로 총 3가지를 쓸 수 있다고 했습니다. 테이블을 확인해보면 ResNet-101은 몇몇 지표에서 성능이 더 좋아짐을 보였지만, ResNet-50으로도 충분하다는 게 저자들의 의견입니다. MobileNetV2의 경우, 모든 지표가 낮게 나왔지만 ResNet-50에 비해 빠르고 작고 BGM에 비해 좋은 성능을 보이기 때문에 trade-off를 고려하여 충분히 사용 가능합니다.
Role of the refinement network
생략하겠습니다.
Patch based refinement vs. Point based refinement
Grefine은 3x3 convolution을 이용하여 receptive filed를 13x13까지 늘렸습니다. 1x1 사이즈의 커널도 이용해보았는데(위의 테이블에 맨 아래 행), 3x3커널(Patch based refinement)가 더 좋은 성능을 보였다고 합니다.
Limitations
본 모델은 휴대용 장비를 통해 입력받는 모든 프레임에 배경 교체가 가능하지만, 작은 동작(small motion)에 대해선 한계가 있습니다. (아마 작은 움직임이나 진동 등이 생기면 에러가 꽤 생긴다는 것 같습니다.) 그 외에도 실패한 케이스는 아래 이미지가 있습니다.

저자들은 좋은 결과를 획득하기 위해선 배경이 단순할 것, 노출/초점/WB(White Balance)를 고정시키고 삼각대를 사용하는 것이 좋다고 합니다.
마치며
4K에서도 높은 fps를 보이며 정량적 및 정성적 지표에서 모두 좋은 결과를 보인 모델입니다. Background matting은 공부해보지 않은 분야여서 장담은 못하지만, SOTA 기법 중에는 가장 좋은 성능을 보이지 않을까 싶습니다.
아쉬운 점은 Limitations에 나왔던 부분인데, 물론 한계점이야 어떤 모델이든 있겠지만 앞서서 크로마키의 단점 중 하나로 그림자를 언급하고서는 똑같은 에러를 보인다는게 살짝 아쉽네요. 하지만 속도 및 연산량에 있어서는 여러 번 fps를 강조할만큼 엄청난 성능 향상이라고 생각합니다.
처음 공부해보는 분야라 틀린 점이 많을 수 있으니 댓글로 남겨주세요.
읽어주셔서 감사합니다. 스크랩 시 출처를 기재해주세요.


