이전에 Salient Object Detection(SOD)에 대한 포스팅을 작성했습니다.
글에 작성하였듯, 2015년부터 deep learning을 이용한 SOD 모델 연구가 활발해지며 다양한 모델이 제안되었습니다.
이번 포스팅에서는 deep learning 기반의 SOD 모델 중 하나인 BASNet에 대해 간단하게 정리해보도록 하겠습니다.
BASNet : Boundary-Aware Salient Object Detection
BASNet은 2019 CVPR paper에 발표된 모델입니다.
BASNet은 이름에서도 볼 수 있듯이, saliency map의 boundary에 quality를 높이기 위해 제안된 모델입니다.
그 동안에 제안되어 온 SOD 알고리즘은 중요한 region을 검출하는 성능에 집중하다보니 예측된 saliency map의 boundary quality가 떨어진다고 합니다.
SOD task를 정확하게 수행하기 어려운 이유는 크게 두 가지를 꼽았습니다.
- Saliency map은 전체 이미지에서 global meaning과 함께 세부적인 물체의 구조들까지 이해하며 추출되어야하나, 실제로 적용되고있는 메소드들은 local-wise features에 의해 map을 결정합니다.
- 대부분의 SOD 메서드들은 Cross Entropy(CE)를 학습 시 손실 함수로 사용하기 때문에 boundary pixel이 흐릿해지는 경향이 있습니다.
이러한 문제점을 해결하기 위해, 본 논문은 정확한 salient object 추출 및 boundary의 quality 성능 향상에 초점을 둔 Boundary-Aware Salient object detection model, 일명 BASNet을 제안합니다.
BASNet에서 제안하는 main contributions은 두 가지입니다.
모델적 측면에서는 predict-refine architecture를 가지고, 학습 측면에서는 손실 함수로 hybrid loss function을 적용한 점입니다.
Model Architecture
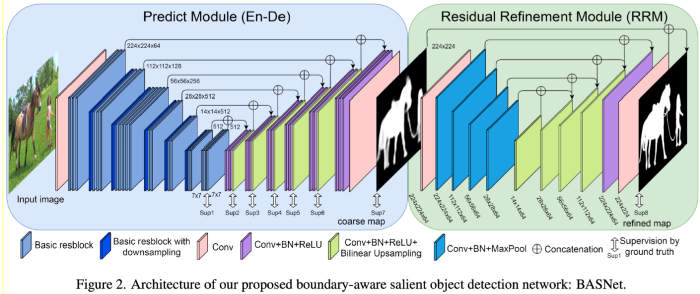
위의 그림은 BASNet의 전체 모델 구조입니다.
BASNet은 두 가지 모듈로 구성되어 있습니다. (Predict module, Residual Refinement Module)
앞단의 predict module에서 saliency map을 획득한 뒤, 뒷 단의 refine module에서 해당 map의 boundary quality를 높여 최종적으로 예측값을 출력합니다.
두 모듈 모두 supervised Encoder-Decoder network 구조를 가지고 있어, Encoder에서 high level의 global contexts를, Decoder에서 low level의 details features들을 획득할 수 있습니다.
1. Predict Module
Predict Module의 back-bone은 ResNet-34의 구조를 따왔습니다.

ResNet-34와 약간의 차이점이 있는데, input layer의 convolution filters가 3x3크기의 64이며 input layer에 pooling operation이 없습니다.
pooling이 없어 두 번째 block 전의 feature map들이 input image와 동일한 resolution을 가지고,
이로 인해 초기의 block에서도 높은 resolution의 feature를 획득하면서 동시에 전체적인 receptive fields를 감소시킬 수 있습니다.
ResNet-34와 동일한 receptive field를 위해, 2개의 stages(blocks)를 추가했습니다.
Encoder와 Decoder 사이에는 bridge stage를 추가하여 high level feature를 넘겨줍니다.
Decoder는 Encoder와 거의 동일한 구조를 가집니다.
over-fitting을 방지하기 위해, 각 decoder stage에서 마지막 layer는 HED(Holistically-Nested Edge Detection)로 구성하였습니다.
2. Residual Refinement Module
Prediction module로부터 획득된 saliency map은 “coasre”한 성질을 지니고 있습니다.
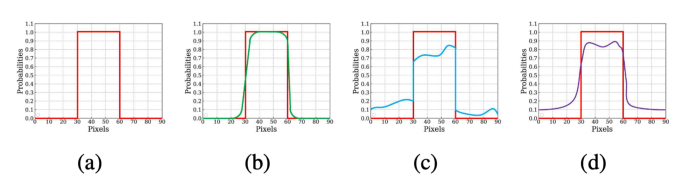
여기서 말하는 coarse란 두 가지 성질을 가지고 있는데, 하나는 “흐릿하고 노이즈가 많은 boundary(Figure 2(b))” 이고,
하나는 “불균형하게(고르지않게) 예측된 regional probabilites(Figure 2(c))” 입니다.
실제로 예측된 coarse saliency map은 두 가지 케이스를 모두 포함하고 있습니다. (Figure 2(d))
따라서 “coarse”함을 감소시키기 위하여, Residual block 기반의 Refinement Module(RM)을 설계하였습니다.
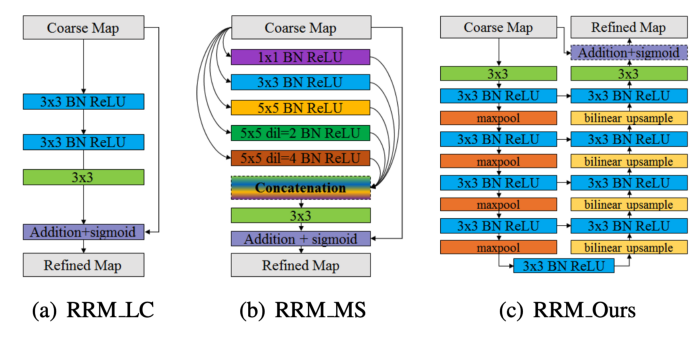
기존에 제안된 RRM(Residual Refinement Module)의 경우
기본적인 residual 구조를 사용하거나 multi-scale을 추가한 정도로만 설계되었다면 (Figure 3 (a),(b)),
BASNet은 RRM 또한 Encoder-decoder 구조를 사용하여 보다 정확하게 saliency map을 refine 합니다.
Hybrid loss
BASNet은 학습 시 전체 output을 summation 하는 loss function을 사용합니다.
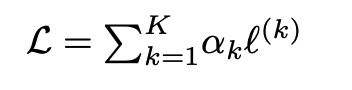
k번째 side output으로부터의 loss들을 각 weight만큼씩 곱하여 모두 더해주는 loss function입니다.
여기서의 “각 loss function”은 이들의 main contributions 중 하나인 “hybrid loss function”입니다.
기존의 depp SOD model들의 문제점 중 하나로, 학습 시 CE loss를 쓰는 점을 제기했습니다.
본 논문에서는 boundary의 quality를 높이기 위해 3개의 loss function을 융합하여 사용합니다.
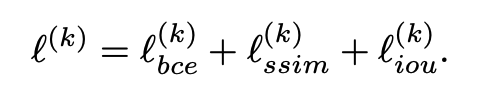
각 loss function은 pixel-wise의 BCE(Binary Cross Entropy) loss, patch-wise의 SSIM(Structural SIMilarity) loss, map-level의 IoU(Intersection over Union) loss입니다.
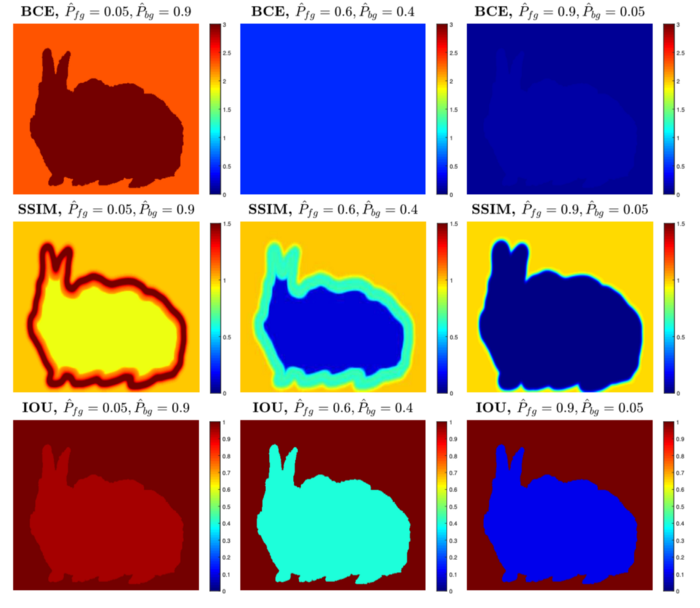
동일한 이미지를 입력했을 때, 각각의 loss function이 object와 boundary, background에 어떻게 영향을 미치는지 예측된 probablitiy로 확인할 수 있습니다.
Experimental Results
Datasets and Implementation
BASNet의 성능을 평가하기 위한 테스트셋으로 6개의 벤치마크 데이터셋을 사용합니다. (SOD, ECSSD, DUT-OMRON, PASCAL-S, HKU-IS, DUTS)
이 중에 DUTS는 training set으로 10,553장의 이미지, test set으로 5,109장의 이미지를 가지고 있습니다.
따라서 모델의 학습은 DUTS-TR을 사용하여 학습했습니다.
Data augmentation을 위해 horizontal flipping을 통해 이미지를 2배로 늘리고,
모든 이미지는 256 x 256으로 resize한 뒤 랜덤하게 224 x 224 크기로 crop합니다.
Adam Optimizer, 400k iterations, batch size는 8 등으로 설정하였습니다.
자세한 내용은 논문의 4.2 section을 참고 바랍니다.
Evaluation Metrics
성능 평가 지표로는 Precision-Recall curve (PR curve), F-measure, Mean Absolute Error(MAE), relaxed F-measure of boundary 4가지를 사용합니다.
- PR curve : GT와 Prediction map간의 preicision과 recall을 계산하여 그린 curve
- F score : Precision과 Recall의 조화 평균
- MAE : 절대 평균 오차
- relaxed F-measure : GT와 prediction map의 boundary를 추출하여 precision과 recall을 계산하여 F score를 계산
각 지표애 대한 자세한 수식은 논문을 참고하세요.
Ablation Study
Ablation study에서는 model architecture와 loss function에 따른 결과를 보여줍니다.
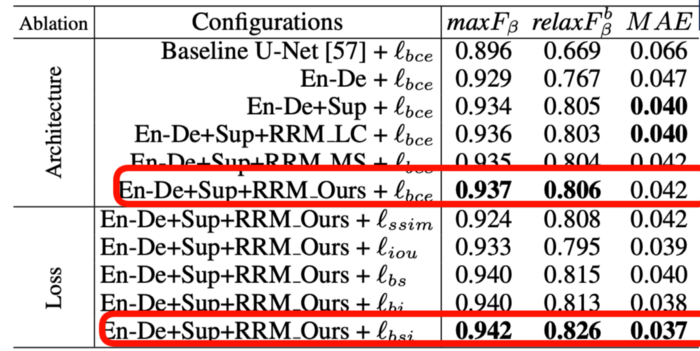
BASNet은 U-net 기반의 Refinement module을 추가하였습니다.
Figure 5에서 보듯, BCE loss를 사용하여 모델 구조만 바꿔 학습했을 시 RRM_Ours를 사용했을 때 좋은 성능을 달성했다고 합니다.

또한 loss function도 바꿔가며 학습했을 때, hybrid loss로 학습한 모델의 성능이 가장 좋았습니다.
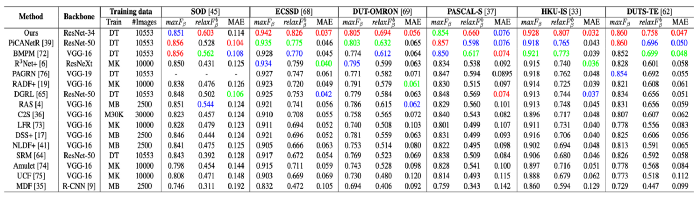
Comparison with SOTA
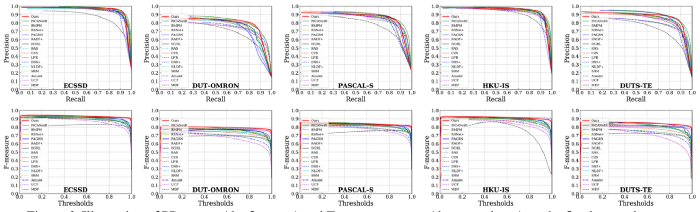
15개의 SOTA 모델과 비교한 결과입니다.
PR curve, F-measure curve, F scores, MAE 등과 qualitative results입니다.

Conclusion
본 논문에서는 end-to-end 구조의 boundary aware model인 BASNet을 제안했습니다.
Encoder-decoder 구조의 Prediction Module과 Refinement Module의 모델,
3개의 loss function을 합친 hybrid loss function을 사용하여
기존의 SOTA 모델들에 비하여 선명한 boundary의 saliency map을 획득함을 보였습니다.
개인적인 의견으로는,
torch 기반의 코드가 github에 공개되어 있고, 코드의 가독성이 매우 좋아 사용자의 편의에 맞게 customizing이 쉽게 가능할 듯 합니다.
모델이 가벼운 편이 아니나, 2021 버전의 preprint에서는 BASNet을 사용한 Web과 Mobile application을 소개합니다.
논문에서는 70fps의 속도로 작성되었으니 생각보다 동작 시간은 괜찮다고 볼 수 있습니다만, 실제로 어플리케이션 구동 시간까지 생각하면 파라미터 경량화도 고려해볼 만한 요소라고 생각합니다.
또한, 2021년 논문에는 SOD 뿐만 아니라 COD(Camouflaged Object Detection) task에 대한 dataset으로도 evaluation합니다.
SOD와 COD 두 task에서 모두 좋은 성능을 보인다고 말하고 싶은 듯 하나,
해당 구조로 어떻게 상반된 Task에서 모두 좋은 성능을 보이는지는 확실히 모르겠습니다.


